
关于影院场次数据的分区方案记录
关于影院场次数据的分区方案记录
背景:我们需要维护一个场次数据表,总数据大概有1000多万条,每天都会有几百万的场次过期,也会新增几百万的场次,这样的大量新增和删除,导致mysql表的碎片化严重。
所以综合一些情况,我们最终采用的分区方案,按每天的日期进行分区
1、先改造场次表,我这边是直接借着这次机会进行重构,新建的表
A.下面是表结构,注意日期用明天和以后的日期,根据自身的数据进行添加分区
CREATE TABLE `wa_schedule_agg` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`schedule_key` char(34) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '场次ID',
`show_date` date NOT NULL COMMENT '放映日期-分区键',
`city_id` int(11) DEFAULT '0' COMMENT '城市id',
`cinema_id` int(11) DEFAULT NULL COMMENT '影院id',
....其他字段
`status` tinyint(1) unsigned DEFAULT '1' COMMENT '1=正常0=过期或移除',
`created_at` int(10) DEFAULT NULL COMMENT '添加时间',
`updated_at` int(10) DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`,`show_date`),
UNIQUE KEY `idx_schedule_key` (`schedule_key`,`show_date`),
KEY `idx_cinema_date` (`cinema_id`,`show_date`),
KEY `idx_cinema_schedule` (`cinema_id`,`status`,`start_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1068637 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
/*!50500 PARTITION BY RANGE COLUMNS(show_date)
(PARTITION p20260122 VALUES LESS THAN ('2026-01-22') ENGINE = InnoDB,
PARTITION p20260123 VALUES LESS THAN ('2026-01-23') ENGINE = InnoDB,
PARTITION p20260124 VALUES LESS THAN ('2026-01-24') ENGINE = InnoDB,
PARTITION p20260125 VALUES LESS THAN ('2026-01-25') ENGINE = InnoDB,
PARTITION p20260126 VALUES LESS THAN ('2026-01-26') ENGINE = InnoDB,
PARTITION p_future VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */;B. 如果用navcat操作的话,可以编辑表,找到选项,找到分区,下面是具体配置
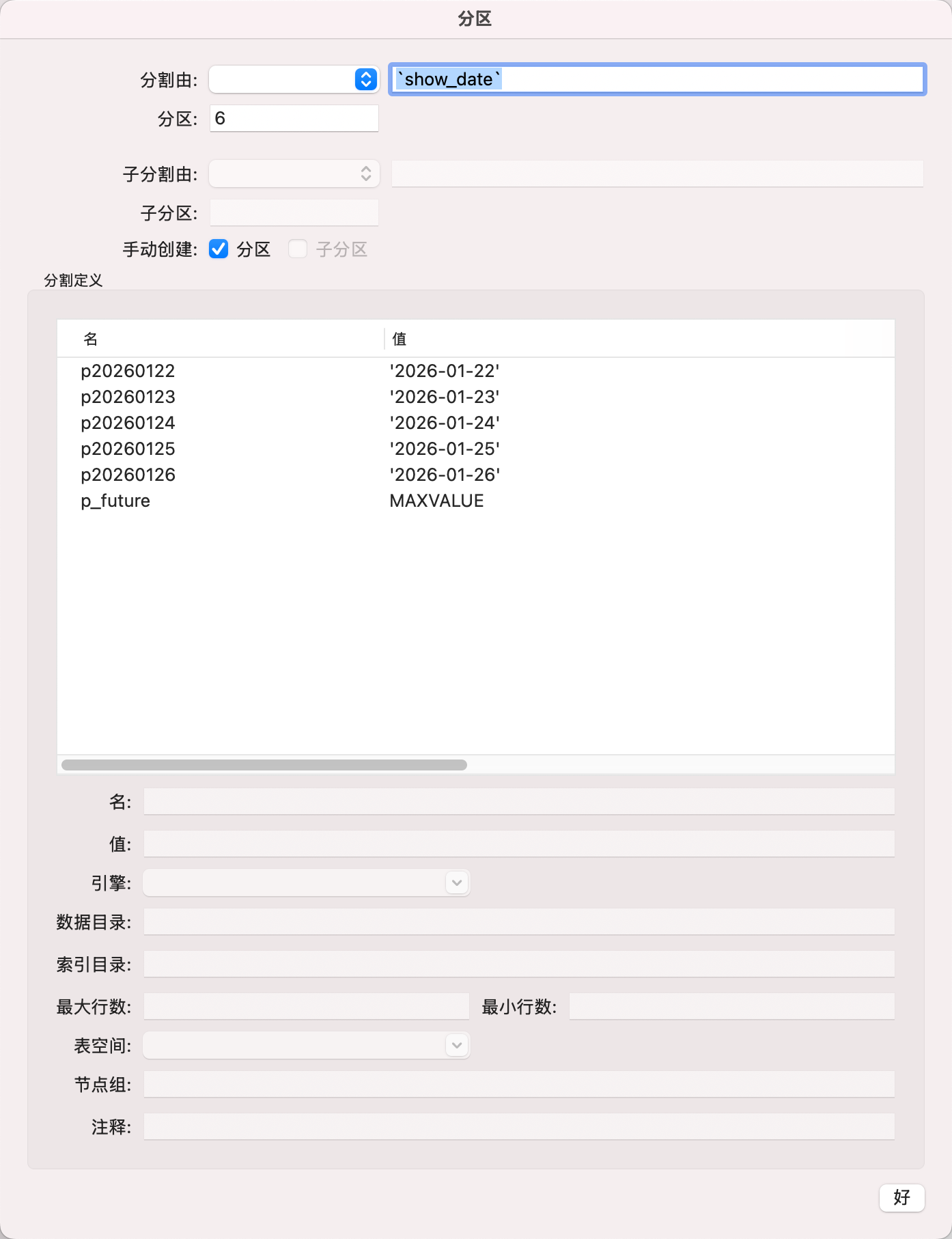 C. 最后一个分区是用来兜底的,这个不适合数据太多
C. 最后一个分区是用来兜底的,这个不适合数据太多
2、这样的话,当数据录入的时候,就会根据数据中的show_date,自动把数据分配到不同的分区,根据下面的命令查看分区的情况
SELECT
PARTITION_NAME AS `分区名`,
PARTITION_DESCRIPTION AS `范围截止日期`,
TABLE_ROWS AS `预估行数`,
ROUND(DATA_LENGTH / 1024 / 1024, 2) AS `数据大小(MB)`,
ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS `索引大小(MB)`
FROM information_schema.PARTITIONS
WHERE TABLE_NAME = '表名'这样就能看到每个分区一般都有数据,如果最后一个分区数据太多,说明你需要增加更多的分区来
3、下面说维护,因为是按照日期进行分区的,后续随着时间流逝,我们还需要自动新增新的日期分区,也要及时的移除过期的分区
我这边是用的阿里云的dsm中的任务编排,每天在业务低谷期执行的
ALTER TABLE wa_schedule_agg DROP PARTITION p${date};
ALTER TABLE wa_schedule_agg REORGANIZE PARTITION p_future INTO (
PARTITION p${date5} VALUES LESS THAN ('${date55}'),
PARTITION p_future VALUES LESS THAN (MAXVALUE)
);
/* 上面的${date}是变量,是指当天的日期,${date5}是指5天后的日期,格式是yyyyMMdd,${date55}也是5天后的日期,格式是yyyy-MM-dd */上面的代码主要做2件事情,第一是移除以今天命名的分区,因为今天命名的分区,里面存的其实是昨天的数据。第二是建立一个新的分区,就是5天后的分区,并且从p_future中把5天后的那天的数据转移到新分区里,这样我们就实现的不间断的维护
4、我们还有一个需求,就是过期的数据,也不能随便删除,也要保存几天,防止有事后需要排查
那么我们就再增加一个新的任务编排,核心的思想是把过期的分区,通过分区迁移的方式归档到一个新的表里
CREATE TABLE `wa_schedule_history_temp` LIKE `wa_schedule_agg`;
ALTER TABLE `wa_schedule_history_temp` REMOVE PARTITIONING;
TRUNCATE TABLE `wa_schedule_history_temp`;
-- 下一步执行完,主表对应的分区就空了,数据全在 temp 表里
ALTER TABLE wa_schedule_agg
EXCHANGE PARTITION p20260121
WITH TABLE wa_schedule_history_temp;
-- 假设今天是 21 号,我们要存的是 20 号的数据
RENAME TABLE wa_schedule_history_temp TO wa_schedule_history_20260120;
-- 删掉 5 天前的历史表
DROP TABLE IF EXISTS wa_schedule_history_20260115;
/* 上面的日期也需要用变量,这里就不赘述了 */另外,需要注意,这个任务,需要在上面那个任务之前进行,另外,这个操作,直接就会导致原表中的相应分区移走,所以上面的任务,第一行的删除就不需要执行了,因为这一步相当于剪切了。
本文链接:
/archives/1768987285030
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
雕刻时光!
喜欢就支持一下吧